
Measuring RAG vs. Fine-tuning ROI for Agent Knowledge
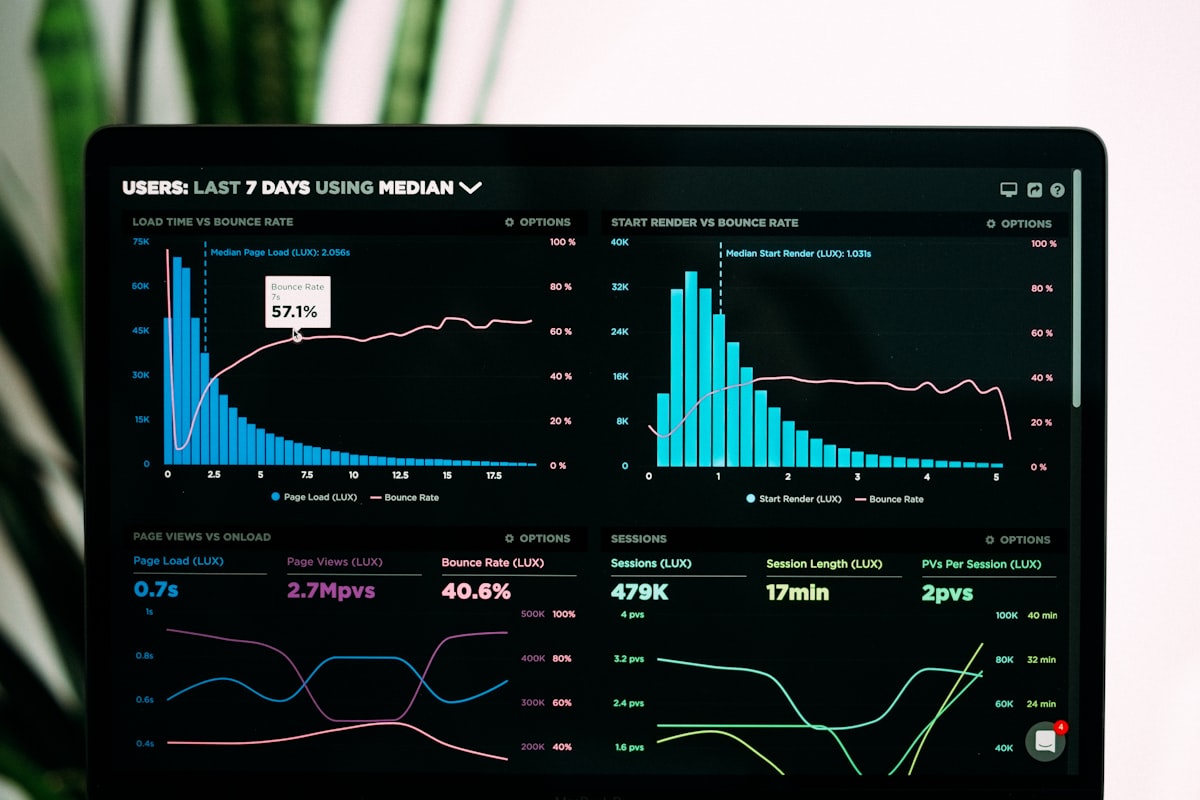
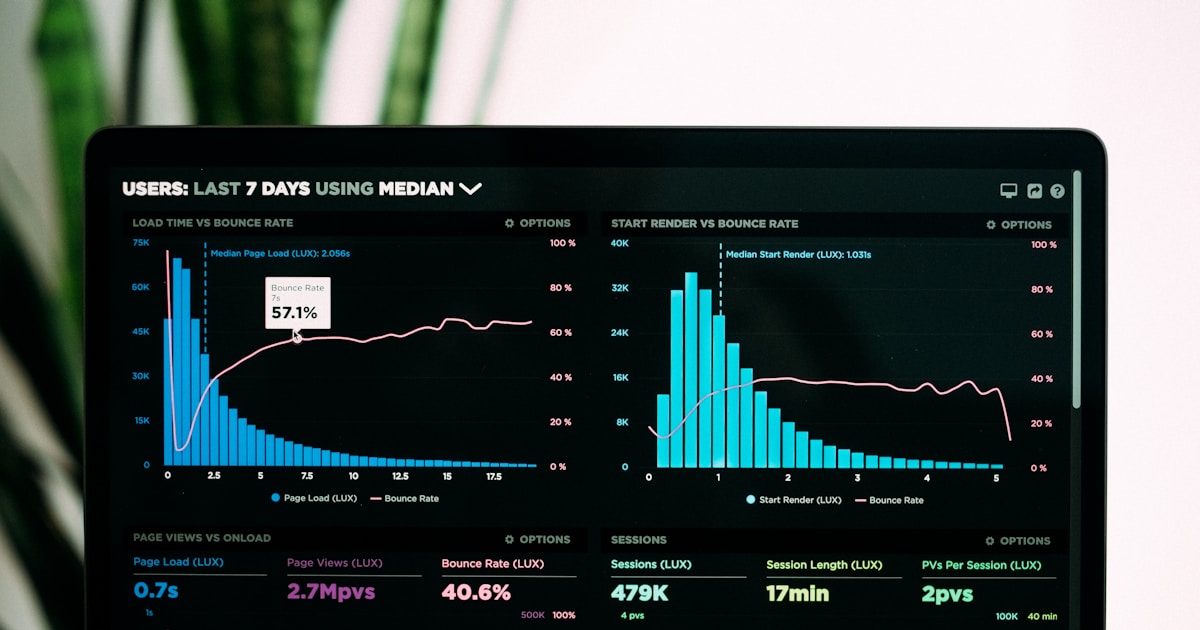
The TCO math has shifted decisively toward RAG for most enterprise agents — unless your query volume exceeds 100K/day with static knowledge.
The TCO math has shifted decisively toward RAG for most enterprise agents — unless your query volume exceeds 100K/day with static knowledge.

gstack packages 21 Claude Code role configurations as SKILL.md files — and that’s both its strength and its limit.

Sparse MoE architectures have won the LLM scaling race — here is how to actually run them at production scale.
OpenAI’s Computer-Using Agent (CUA) navigates any website by seeing and reasoning — no DOM, no selectors. This deep dive covers how CUA works, how it compares to Anthropic’s approach and traditional RPA, and where the technology still falls short.

A practical guide to hybrid episodic-semantic memory architectures that enable production AI agents to maintain coherent behavior across sessions without hitting context window limits.

The MAST taxonomy provides the first systematic framework for diagnosing why enterprise AI agents fail in production IT environments.
Accuracy benchmarks built for static LLMs fail completely when applied to AI agents. Here’s the three-layer evaluation framework, four production KPIs, and CI/CD integration patterns that actually work.

Your LLM bill doesn’t have to scale linearly with usage. This production playbook walks through six battle-tested techniques — from smart model routing to token-efficient RAG — that engineering teams are combining to cut inference spend by 50% or more without degrading quality.
MCP’s USB-C analogy sounds perfect—but the reality involves JSON-RPC servers, stateful sessions, and infrastructure overhead. Here’s why a simple markdown file often beats a protocol-based approach.

How MCP solves the M×N integration problem and why Block, Replit, Zed, and Sourcegraph are betting on Anthropic’s open standard for AI agent interoperability.